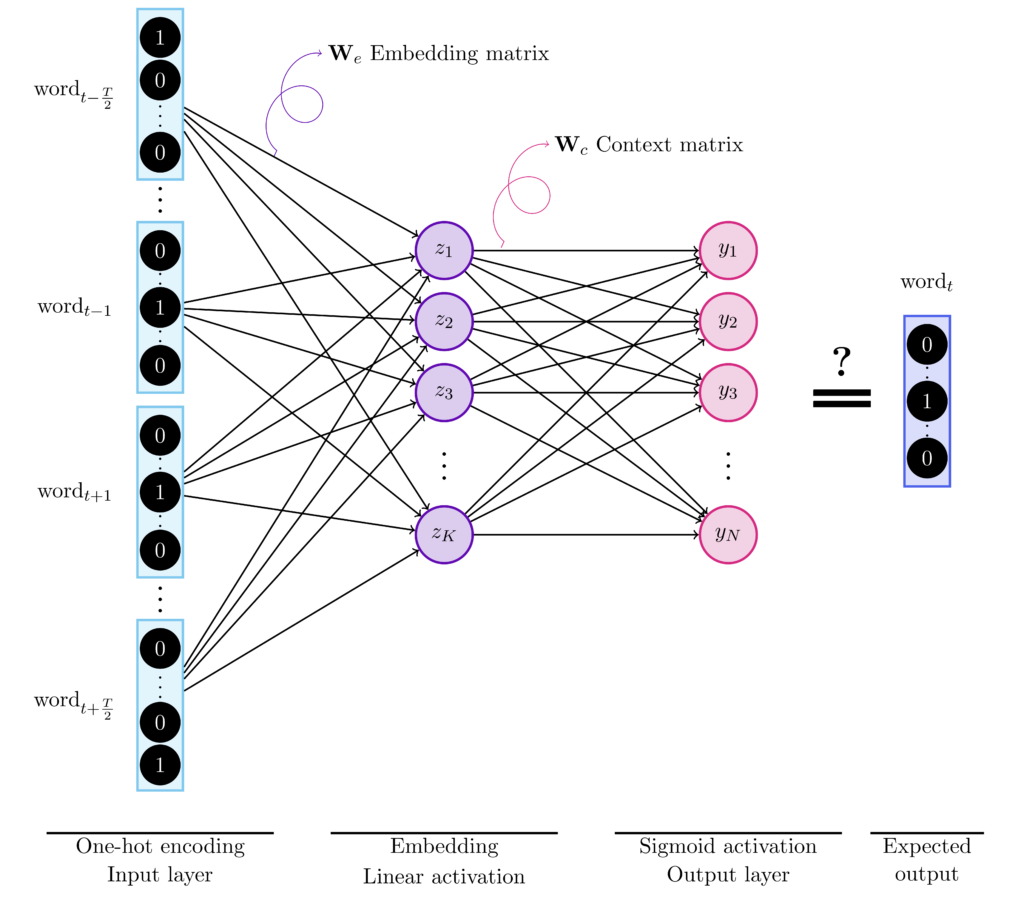
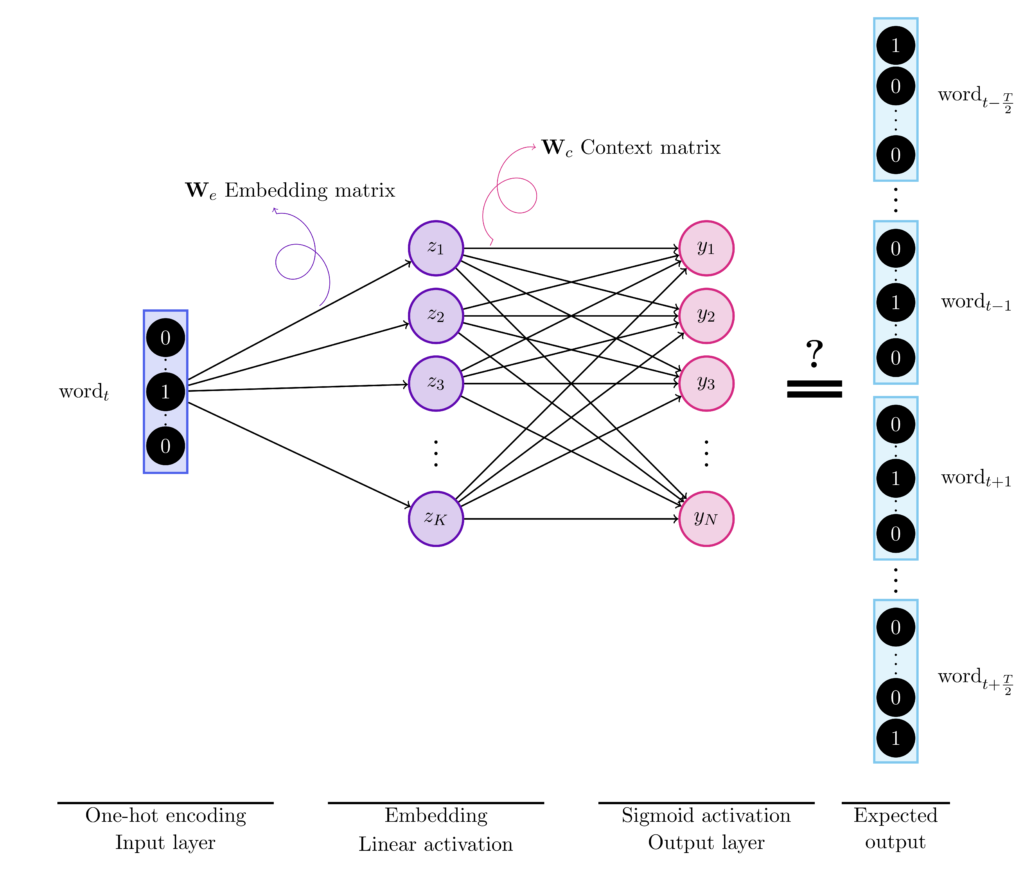
Let us use as a corpus a paragraph from Alice’s adventures in wonderland by Lewis Carroll,
“Alice was beginning to get very tired of sitting by her sister on the
bank, and of having nothing to do: once or twice she had peeped into the book her sister was reading, but it had no pictures or conversations in it, ‘and what is the use of a book,’ thought Alice ‘without pictures or
conversation?'”
The words of this corpus will be one-hot encoded using a one to $N$ scheme, where $N$ refers to the size of the vocabulary or the number of unique words. For instance, “Alice” –> [1, 0, \dots] and “was”–> [0,1,0,\dots].
Then, if we consider a window of length $T = 4$ on the first sentence, the words “Alice”, “was”, “to”, “get” are the inputs to the CBOW architecture while the target is “beginning”.
The size of the input of the hidden layer, $K$, is the size of the embeddings that is usually set larger than 100. The output of the hidden layer is the word’s vector representation.